

Table of Links
4. Ablations on synthetic data
5. Why does it work? Some speculation
7. Conclusion, Impact statement, Environmental impact, Acknowledgements and References
A. Additional results on self-speculative decoding
E. Additional results on model scaling behavior
F. Details on CodeContests finetuning
G. Additional results on natural language benchmarks
H. Additional results on abstractive text summarization
I. Additional results on mathematical reasoning in natural language
J. Additional results on induction learning
K. Additional results on algorithmic reasoning
L. Additional intuitions on multi-token prediction
4. Ablations on synthetic data
What drives the improvements in downstream performance of multi-token prediction models on all of the tasks we have considered? By conducting toy experiments on controlled training datasets and evaluation tasks, we demonstrate that multi-token prediction leads to qualitative changes in model capabilities and generalization behaviors. In particular, Section 4.1 shows that for small model sizes, induction capability—as discussed by Olsson et al. (2022)—either only forms when using multi-token prediction as training loss, or it is vastly improved by it. Moreover, Section 4.2 shows that multi-token prediction improves generalization on an arithmetic task, even more so than tripling model size.
4.1. Induction capability
Induction describes a simple pattern of reasoning that completes partial patterns by their most recent continuation (Olsson et al., 2022). In other words, if a sentence contains “AB” and later mentions “A”, induction is the prediction that the continuation is “B”. We design a setup to measure induction
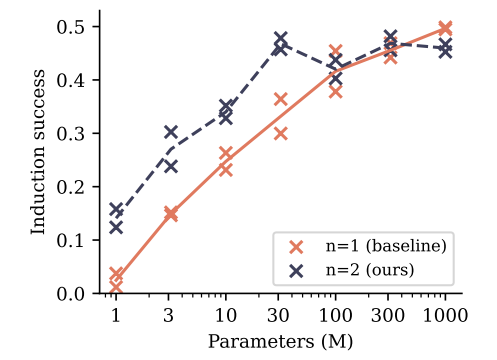
capability in a controlled way. Training small models of sizes 1M to 1B nonembedding parameters on a dataset of children stories, we measure induction capability by means of an adapted test set: in 100 stories from the original test split, we replace the character names by randomly generated names that consist of two tokens with the tokenizer we employ. Predicting the first of these two tokens is linked to the semantics of the preceding text, while predicting the second token of each name’s occurrence after it has been mentioned at least once can be seen as a pure induction task. In our experiments, we train for up to 90 epochs and perform early stopping with respect to the test metric (i.e. we allow an epoch oracle). Figure 7 reports induction capability as measured by accuracy on the names’ second tokens in relation to model size for two runs with different seeds.
We find that 2-token prediction loss leads to a vastly improved formation of induction capability for models of size 30M nonembedding parameters and below, with their advantage disappearing for sizes of 100M nonembedding parameters and above.[1] We interpret this finding as follows: multitoken prediction losses help models to learn transferring information across sequence positions, which lends itself to the formation of induction heads and other in-context learning mechanisms. However, once induction capability has been formed, these learned features transform induction
into a task that can be solved locally at the current token and learned with next-token prediction alone. From this point on, multi-token prediction actually hurts on this restricted benchmark—but we surmise that there are higher forms of in-context reasoning to which it further contributes, as evidenced by the results in Section 3.1. In Figure S14, we provide evidence for this explanation: replacing the children stories dataset by a higher-quality 9:1 mix of a books dataset with the children stories, we enforce the formation of induction capability early in training by means of the dataset alone. By consequence, except for the two smallest model sizes, the advantage of multi-token prediction on the task disappears: feature learning of induction features has converted the task into a pure next-token prediction task.
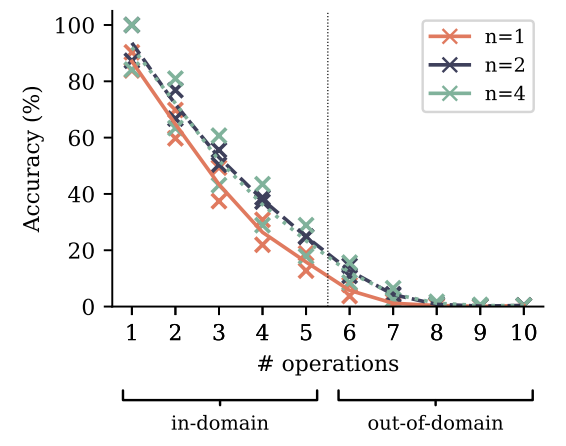
4.2. Algorithmic reasoning

Multi-token prediction improves algorithmic reasoning capabilities as measured by this task across task difficulties (Figure 8). In particular, it leads to impressive gains in out-of-distribution generalization, despite the low absolute numbers. Increasing the model size from 30M to 100M parameters, on the other hand, does not improve evaluation accuracy as much as replacing next-token prediction by multi-token prediction does (Figure S16). In Appendix K, we furthermore show that multi-token prediction models retain their advantage over next-token prediction models on this task when trained and evaluated with pause tokens (Goyal et al., 2023).
Authors:
(1) Fabian Gloeckle, FAIR at Meta, CERMICS Ecole des Ponts ParisTech and Equal contribution;
(2) Badr Youbi Idrissi, FAIR at Meta, LISN Université Paris-Saclayand and Equal contribution;
(3) Baptiste Rozière, FAIR at Meta;
(4) David Lopez-Paz, FAIR at Meta and a last author;
(5) Gabriel Synnaeve, FAIR at Meta and a last author.
This paper is
[1] Note that a perfect score is not reachable in this benchmark as some of the tokens in the names in the evaluation dataset never appear in the training data, and in our architecture, embedding and unembedding parameters are not linked.